 This is a guest post from Eldad Uzman, Automation Architect at Merck on how to distribute JMeter clients across different regions. You can read more from Eldad at Medium.
This is a guest post from Eldad Uzman, Automation Architect at Merck on how to distribute JMeter clients across different regions. You can read more from Eldad at Medium.
When running load tests, you want to make sure your testing setup is as close to production setup as possible. One of the many things that would contribute to high validity of load tests is the ability to distribute the load across different regions. Thanks to RedLine13 this is done very easily using JMeter, leveraging AWS infrastructure. In this article we will build up the different stages of creating and running a distributed load test across different regions.
The code examples referenced in this article can all be found under my DistributedLoadTesting-Demo repository on GitHub.
Stage 1: Basic Distribution
This is the most simple and straight forward stage. Our test script generates user IDs in the setup and then re-use these IDs in the main thread.
JMeter Test Plan (JMX file):
First, let us take a look at the “User defined variables“:
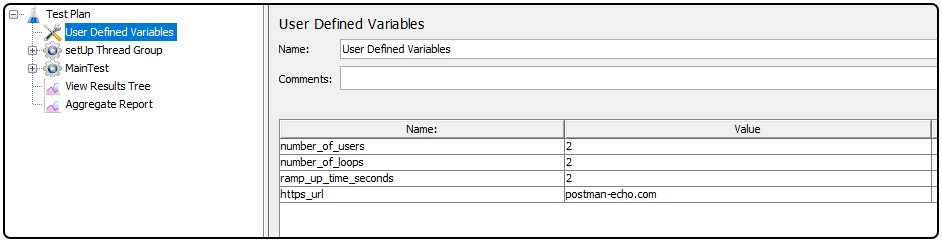
In this super light example, we have two users, executing two loops, starting at a ramp up time of 2 seconds. They will interact with the Postman Echo API which will serve as our dummy server under test. In the JMX setup thread we will generate a unique user ID and store it in a property.
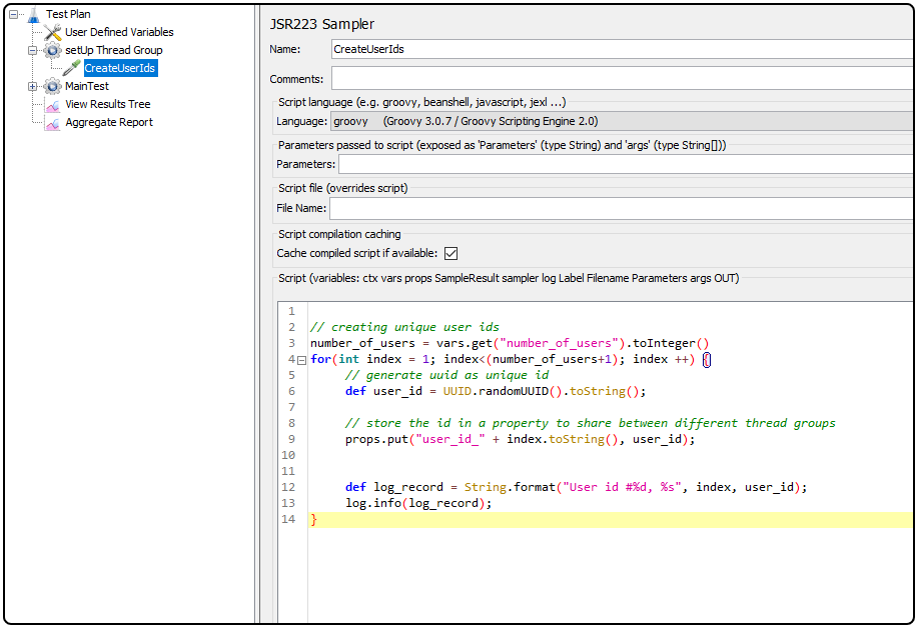
As you can see, each user ID is saved to a property named in the convention of “user_id_${serial_number}”.
Now, we can reference the property in each thread in the test thread group (“Main Test“). Under the “Lets begin” element, we will grab the correct user ID by taking the property corresponding to the thread number. From there, it is then stored it in the variable named “user_id“. This variable is only shared within the thread.
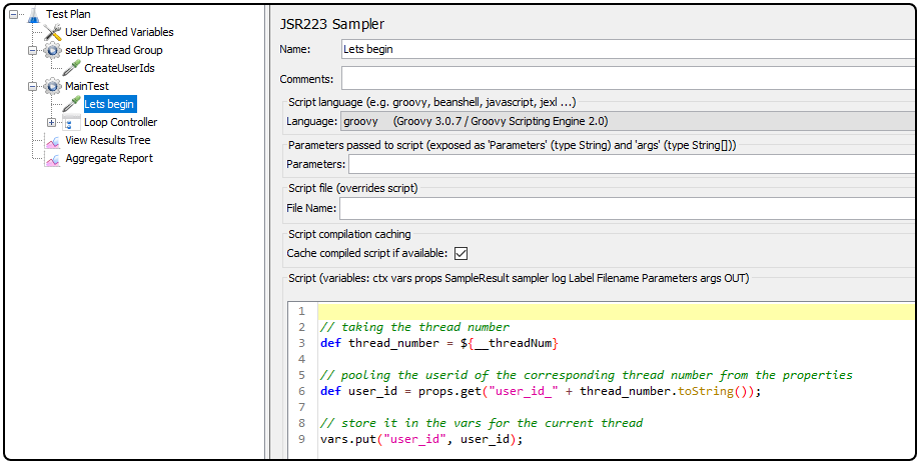
Now, let’s use this user ID:
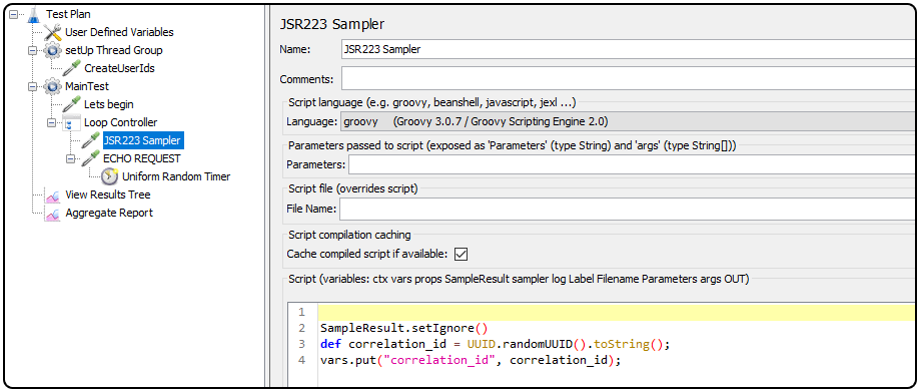
We have a loop controller executing the number of loops specified in the user defined variables (two in our case) and the first step in the loop is to generate a per-loop correlation ID. Therefore, the user IDs are re-used, and in each iteration we generate a new correlation ID for the message. This is very important for traceability and observability.
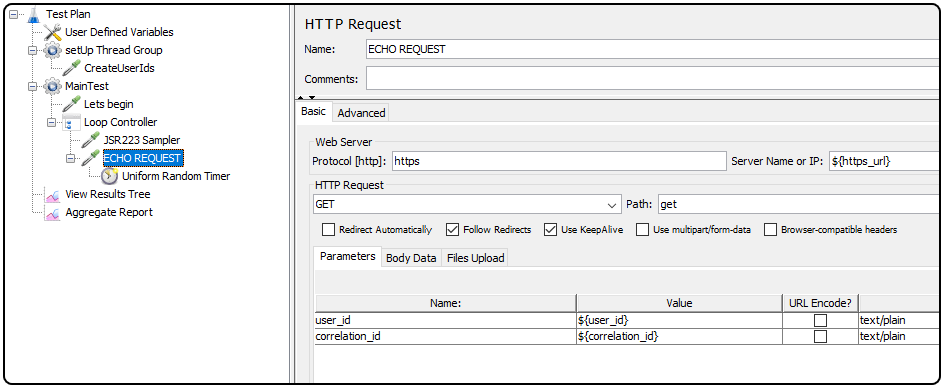
After all is set and done, we can send our HTTP request:
Finally, let us run this script locally and see the results in the tree view:
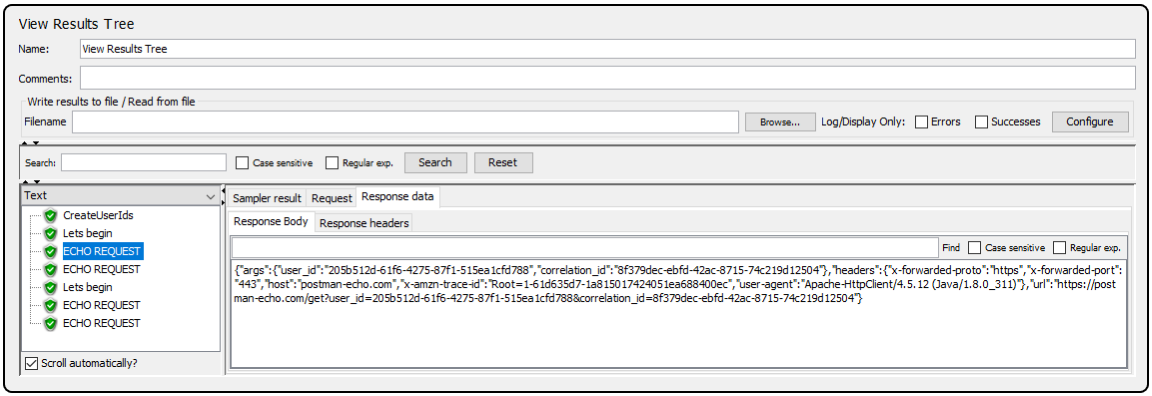
We’ve got four echo requests as expected, and each of these requests has a response with the expected fields.
RedLine13:
Let’s create a new JMeter test in RedLine13 containing our JMX test plan file only:
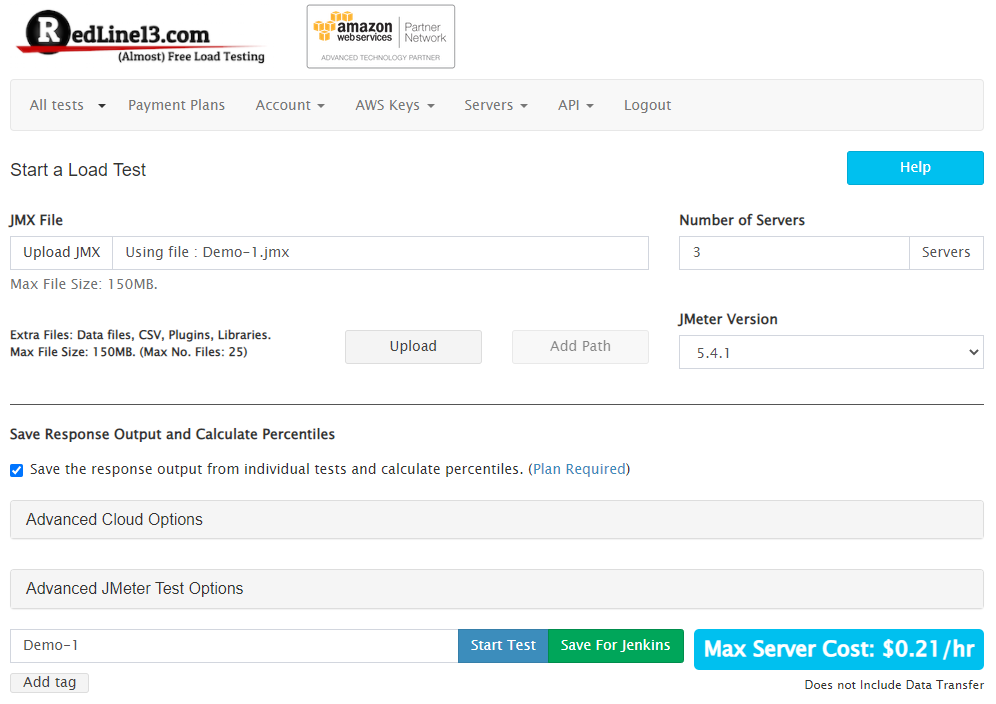
Now let’s distribute across three regions in the “Advanced Cloud Options” section:
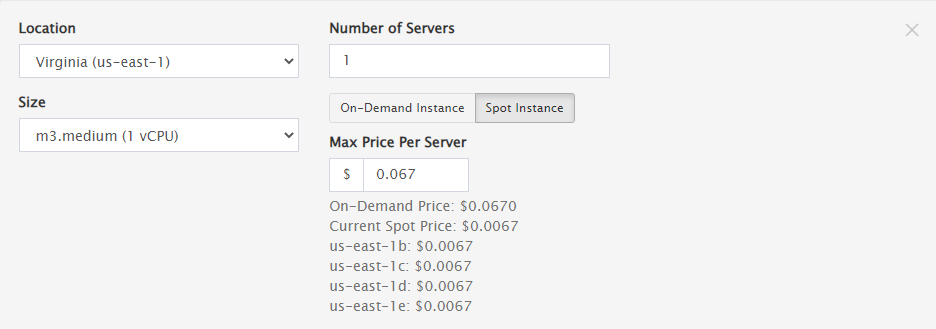
Region 1 – US-East (Virginia)
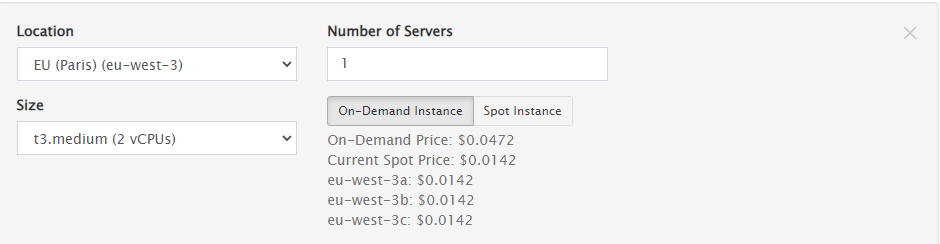
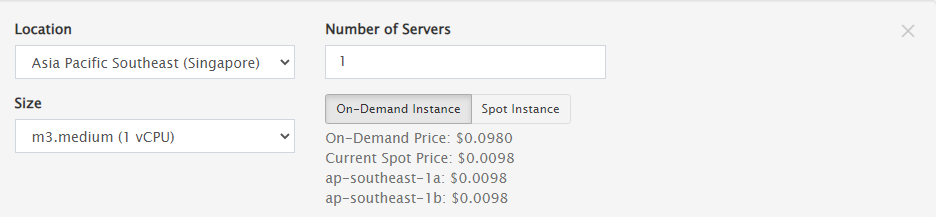
Some easy math lends us to expect a total of 12 requests (from the “ECHO REQUEST” element). Let’s run the test and check the results:
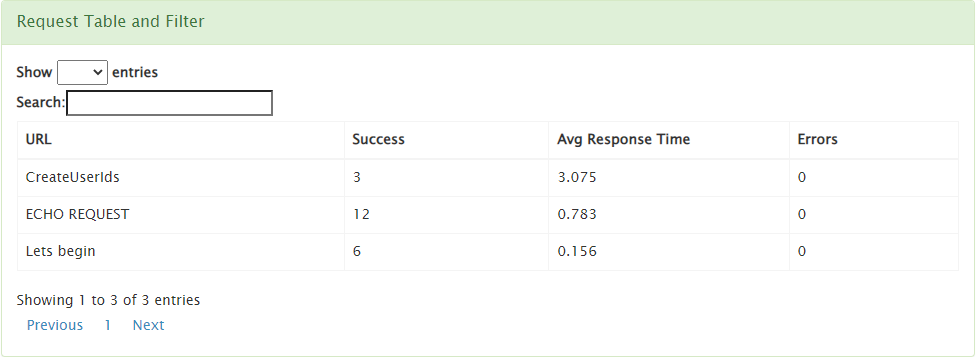
Limitations:
This naïve approach works out pretty well if the server under test is static. That is, if there is no caching mechanism per user, you can generate a new user ID with each test execution. However, the moment you introduce caching to your server under tests (and this is the most common case) your tests become invalid and unreliable as they are not reflective of real-life situation.
Stage 2: Reusable User ID
This time around, we will use a CSV file to reuse these user IDs instead of creating them with each test execution.
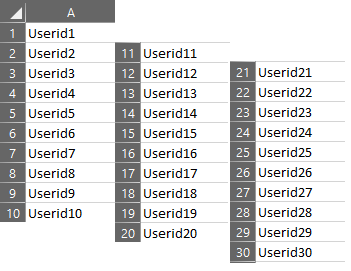
CSV file:
The structure of our CSV file is straight-forward and takes the form of a single column:
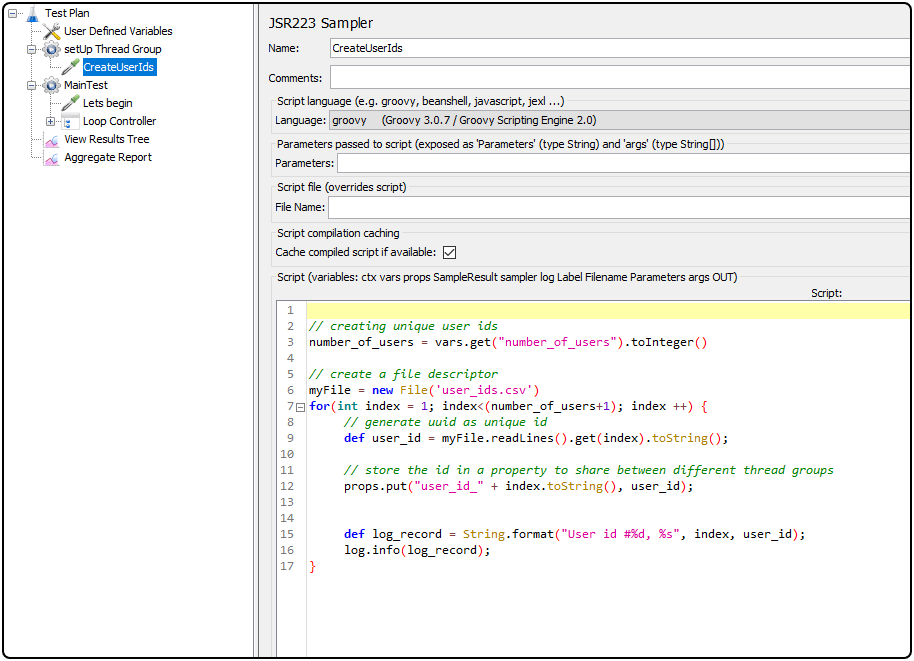
JMeter Test Plan (JMX file):
In the JMX file, instead of generating UUIDs we will take the IDs from the CSV file:
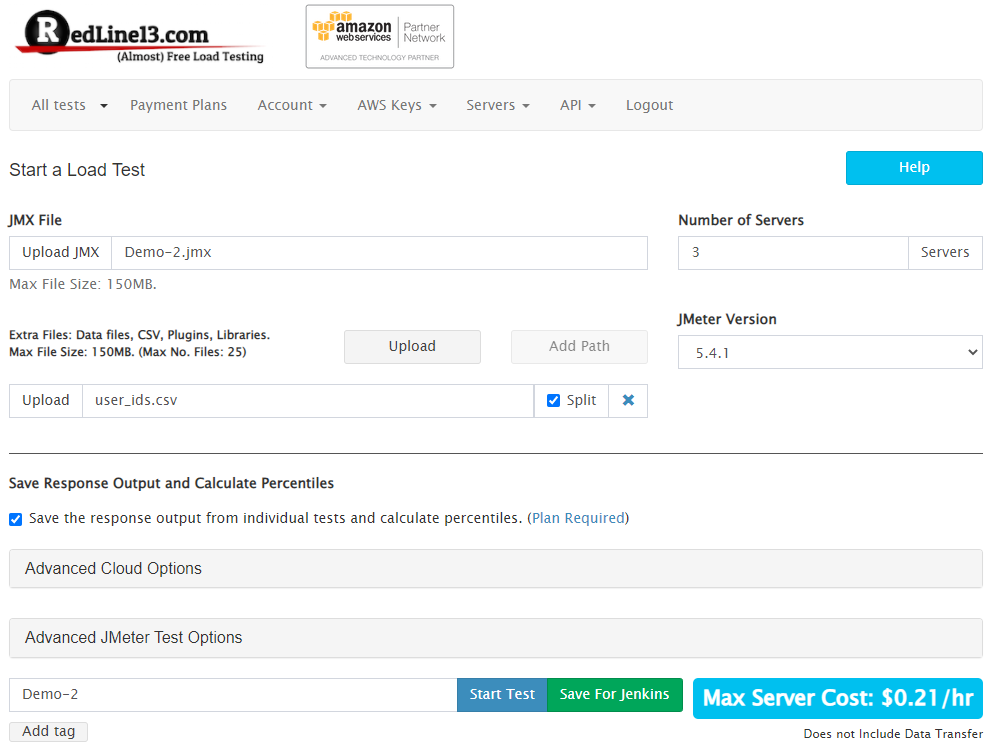
RedLine13:
In RedLine13 we will only upload the CSV file and split it to the different load agents.
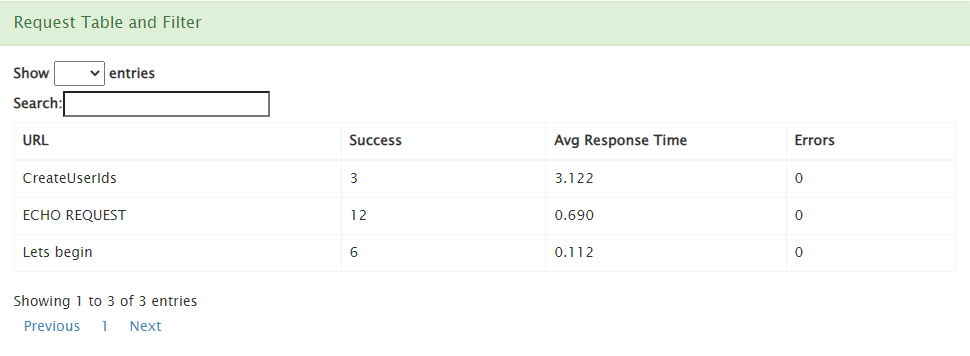
Let’s run the test and see the results:
Limitations:
Reusing data for tests in this fashion works well if your server undertest is region agnostic. In other words, all requests across the different regions are treated in the same way. But what happens when you are using some regional optimization service like AWSs global accelerator?
Now your caching mechanism is quite different. So, let’s take “Userid1” for example. In our first test execution it appeared in a US region, and it was cached in the US, and then in the next test execution it appeared an EU region and consequently cached in the EU. The CSV is being split over the different load agents irrespective of their region, in this can affect your cache in a way that your application wouldn’t be operating in the real life.
Stage 3: Region-specific User IDs
In order to make the distribution region aware, we need to first now what region our load agent is at.
This is very straight forward with AWS instance identity server
We can use this server to retrieve data about our EC2 instance from within the instance itself! Let’s write a short shell script to do that for us. We’ll start by running the following command:
curl http://169.254.169.254/latest/dynamic/instance-identity/document
The expected output should look similar to the following:
{ "accountId" : "[]", "architecture" : "x86_64", "availabilityZone" : "eu-central-1b", "billingProducts" : null, "devpayProductCodes" : null, "marketplaceProductCodes" : null, "imageId" : "[]", "instanceId" : "[]", "instanceType" : "t3.small", "kernelId" : null, "pendingTime" : "2021-12-20T15:16:02Z", "privateIp" : "[]", "ramdiskId" : null, "region" : "eu-central-1", "version" : "2017-09-30" }
To make it more specific to our purpose lets filter out the irrelevant fields by executing this command:
curl http://169.254.169.254/latest/dynamic/instance-identity/document| grep region|awk -F\" '{print $4}'
The expected output in this case would be:
eu-central-1
Great! Now we can tell the region we generate our load from!
CSV Files:
For the next steps, we will create a separate CSV file for each region:
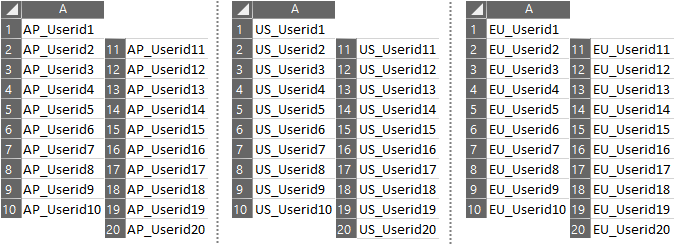
Shell Script:
Our shell script will deduce the identity of our load agent and select the correct CSV file accordingly.
#!/bin/bash REGION=`curl http://169.254.169.254/latest/dynamic/instance-identity/document |grep region|awk -F\" '{print $4}'` echo $REGION REGION_SIGN=${REGION:0:2} echo $REGION_SIGN REGION_SIGN=$(echo $REGION_SIGN | tr 'a-z' 'A-Z'| xargs) echo $REGION_SIGN FILENAME="user_ids_${REGION_SIGN}.csv" echo $FILENAME cp $FILENAME user_ids.csv
JMeter Test Plan (JMX file):
The only change to the JMX file is to execute the shell script at the setup:
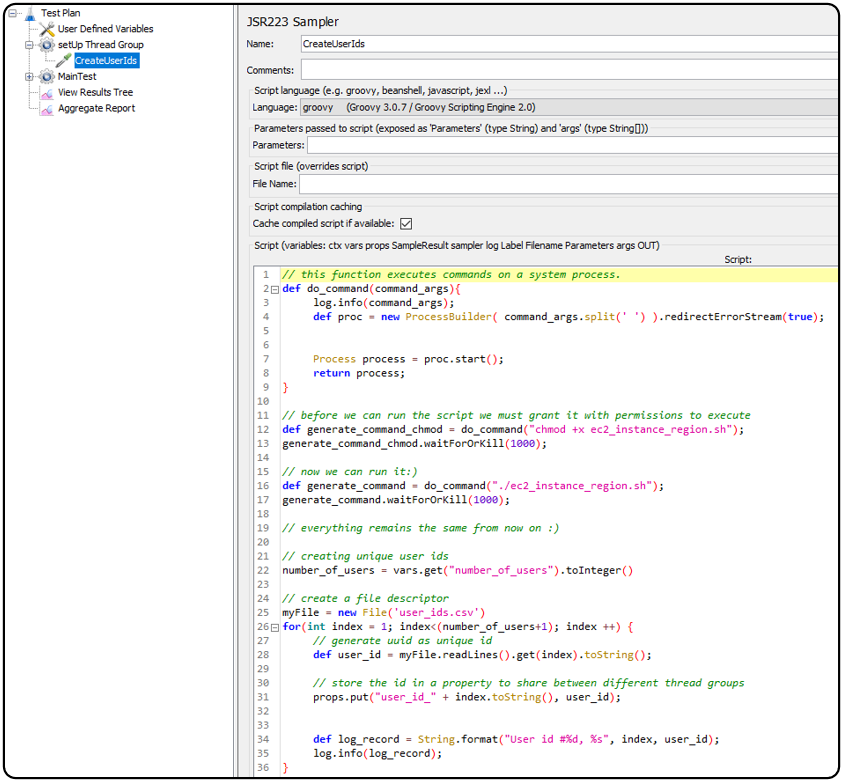
We gave the script permissions to run and then we executed it. The rest of the script can remain unchanged.
RedLine13:
Instead of one global CSV file, we will upload three CSV files (one per region), in addition to the shell script:
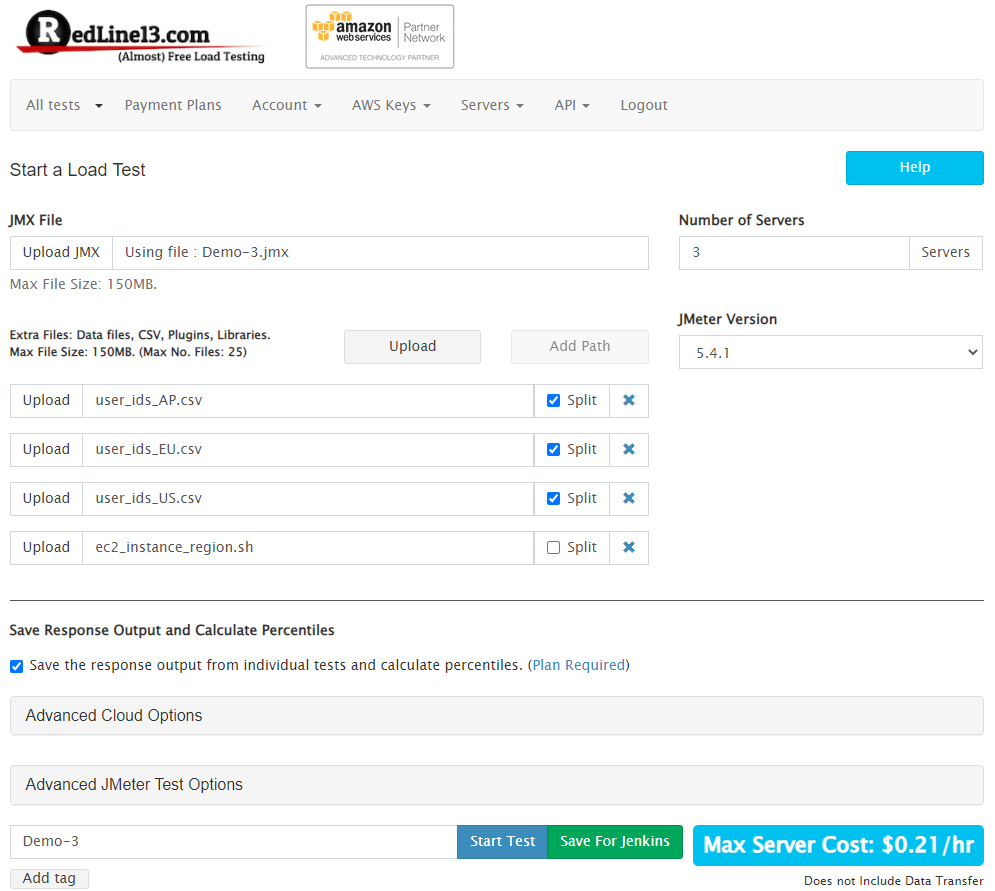
Now we can run this script and see the results:
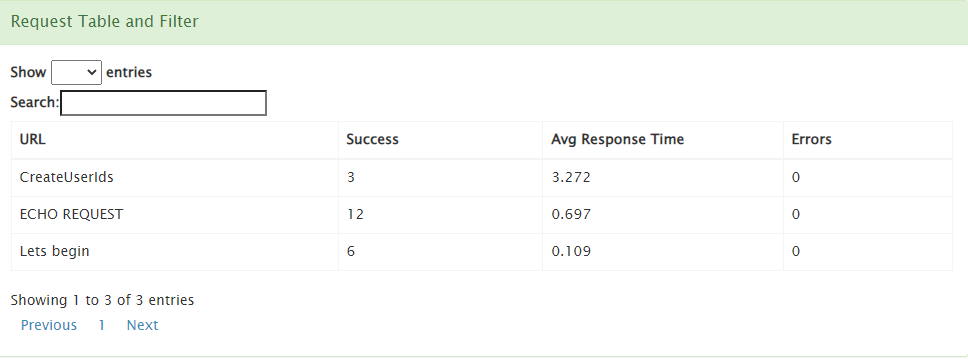
Conclusion
In this article we saw how easily we can progress between the three stages and what are the limitations of each stage. The naïve solution of generating user IDs each test could work well in some situations. However, in most situations this is not a realistic scenario. Re-using user IDs with a fixed list is another option but you must take into account the caching mechanism of the application and how it interacts with some other solutions – namely AWS Global Accelerator. We can use AWS identity services to deduce the region from where we generate our load and then reuse our user IDs in a more intelligent way, insuring high validity to our test cases.
Did you know that RedLine13 offers a free trial plan that includes time-limited full access to most of our advanced features? Sign up now and distribute your JMeter clients across different regions