Gatling Support
This post is a bit delayed because the conversation really started at AWS re:Invent. As noted in the review post by Bob it was a great event and we appreciated the love from many folks coming to our less than impressive booth. While we received many requests for info on our Jenkins and JMeter integration, quite a few folks asked us about Gatling support.
Why Gatling.io for RedLine?
In building Redline we were thinking about the ability to scale out load tests at reasonable cost. It never mattered to us which tool to use for load testing JMeter, Gatling, or custom script (use the tool that you prefer). Stéphane Landelle’s slide deck on Gatling – Load Testing Made Easy describes how it differs from the other tools and can give you background on why so many people think Gatling is cool!
Why RedLine for the Gatling Community?
RedLine provides a very simple way to deploy Gatling tests at scale. Need 100 servers to run your Gatling test for an hour – RedLine manages all of the deployment for you and it deploys on your AWS account – so all you are paying for is the hour of EC2 cost (and since we can deploy spot instances, it can be VERY cheap). We are not charging you anything extra for that deployment – just raw AWS cost that is part of your AWS account. We take care of spinning the instances up and down and then aggregating all the resulting data. We charge $30 per month as a flat rate to fulfill this service.
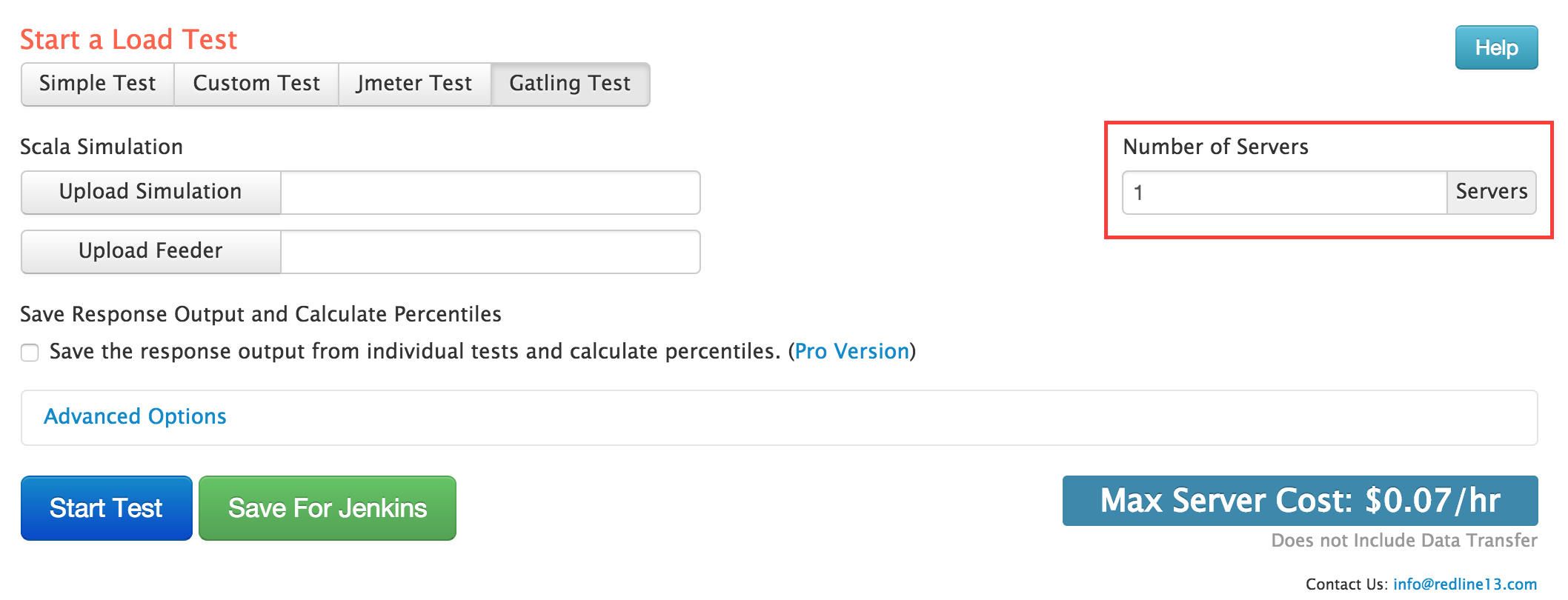
Our Gatling support
We provide a very straight-forward integration – load your Gatling Scala file, and if needed feeder file. Configure how many servers you want and press ’Start Test’! The help page for using Gatling details the steps with some screen shots and is available at https://www.redline13.com/
Example Test Run
Here is an example output of a Gatling load test run across 20 servers. We can see much of the test output here including details on the test servers, the output files containing the Gatling logs, and response time graphs.
From Gatling test plan we can see we setup 10 users to start at once and 500 users to ramp over 10 minutes.
setUp(scn.inject(
atOnceUsers(10),
rampUsers(500) over(600 seconds)
)).protocols(httpProtocol)
Our test started with 20 servers each scaling to 510 users over 10 minutes. We ran this test with 5 servers in these regions Virginia, California, Oregon, and Ireland.
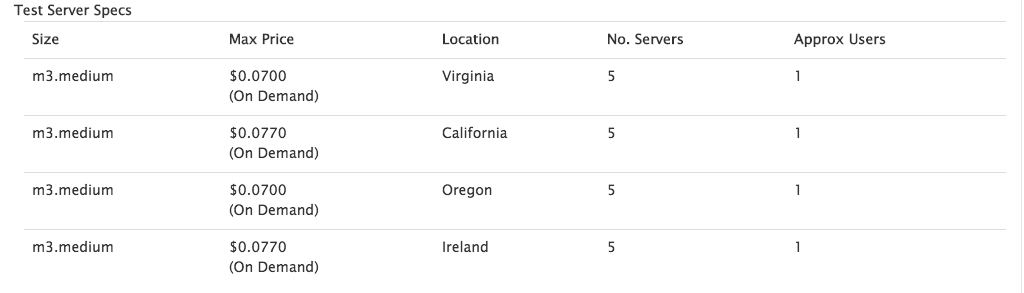
The test ran for about 15 minutes and executed as 10,200 users from 4 regions. Running with On Demand instances the test cost $1.48.

The average result from the Gatling test plan took somewhere between 100 and 120 seconds. This test ran through a few pages and pulled resource files as well. Here is an excerpt from the list of test servers.
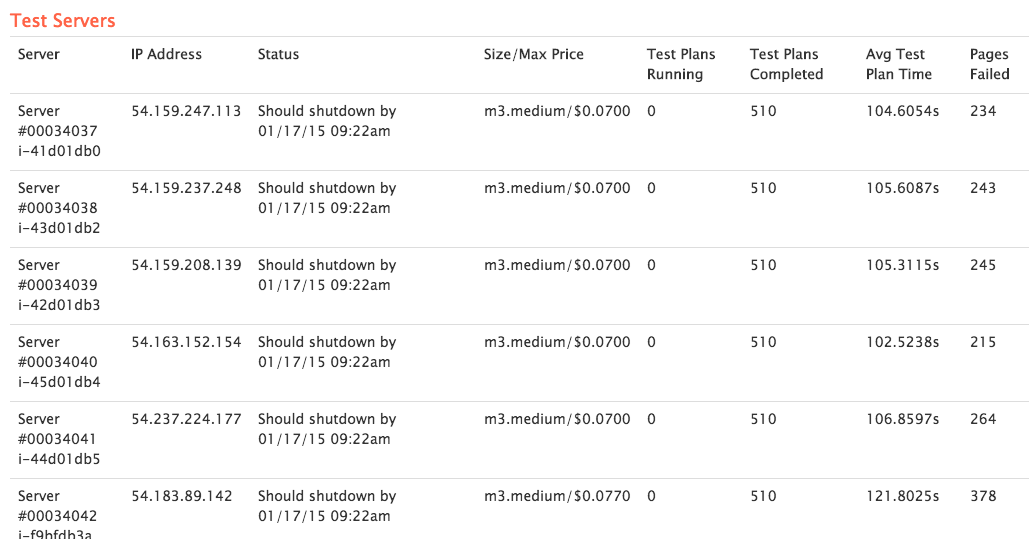
With pro version you can request the output files
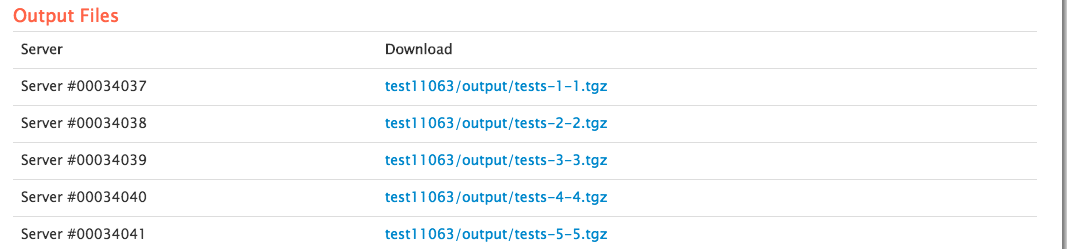
and percentiles.

Graphs provided include – Request rate and average response time
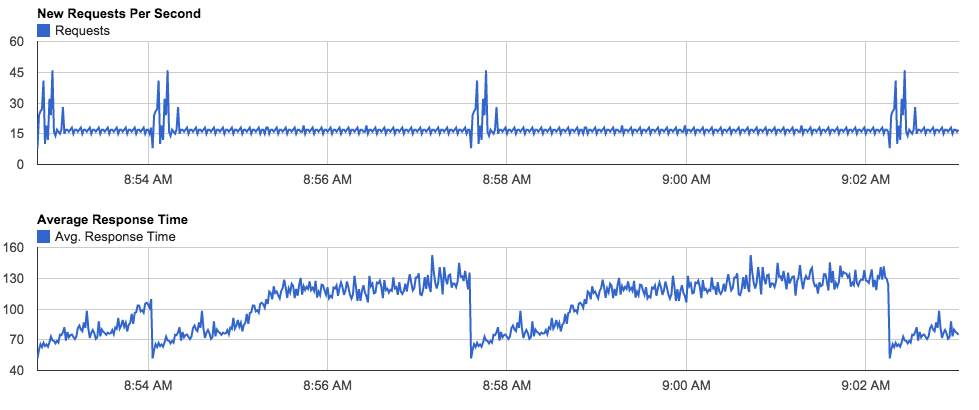
– Per page request rate and response time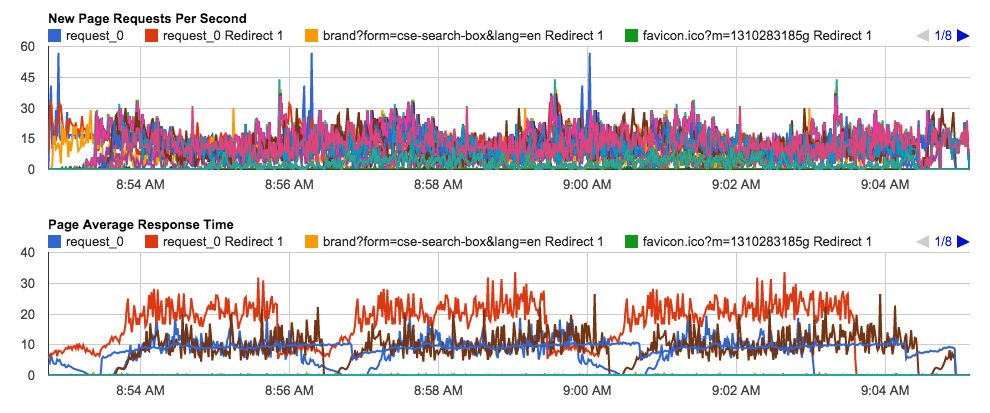
– Load Agent CPU and Network Traffic.
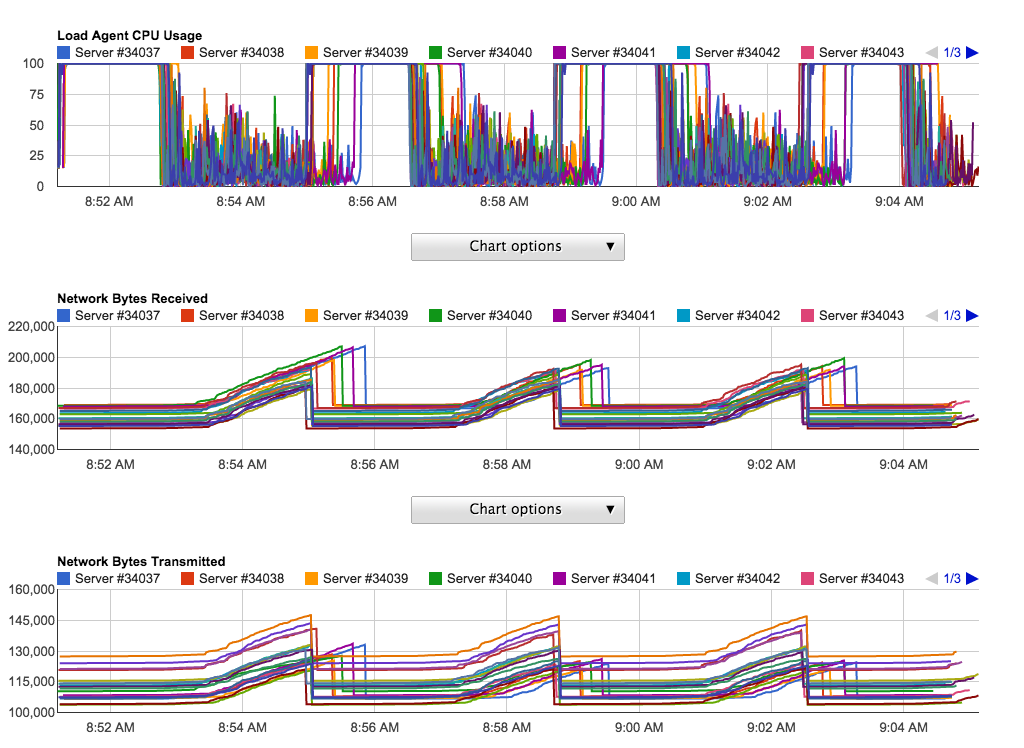
Page and request errors are reported back, obviously our test site did not fair too well.

1 Comment
Comments are closed.